
Overview
When I worked in the startup, our goal was to set a monitoring solution to monitor the components of infrastructure, such as virtual machinery and applications – all while staying in a limited budget and in a short time. To achieve this, I chose open source tools such as Prometheus, Grafana, Mimir and Nginx. As we were hosted in Google Cloud, the easiest way to start with infrastructure and applications was to start with these tools, the implementation of Google Governor Engine (GKE). However, this guide can be easily adjusted to set the tracking on each cloud platform.
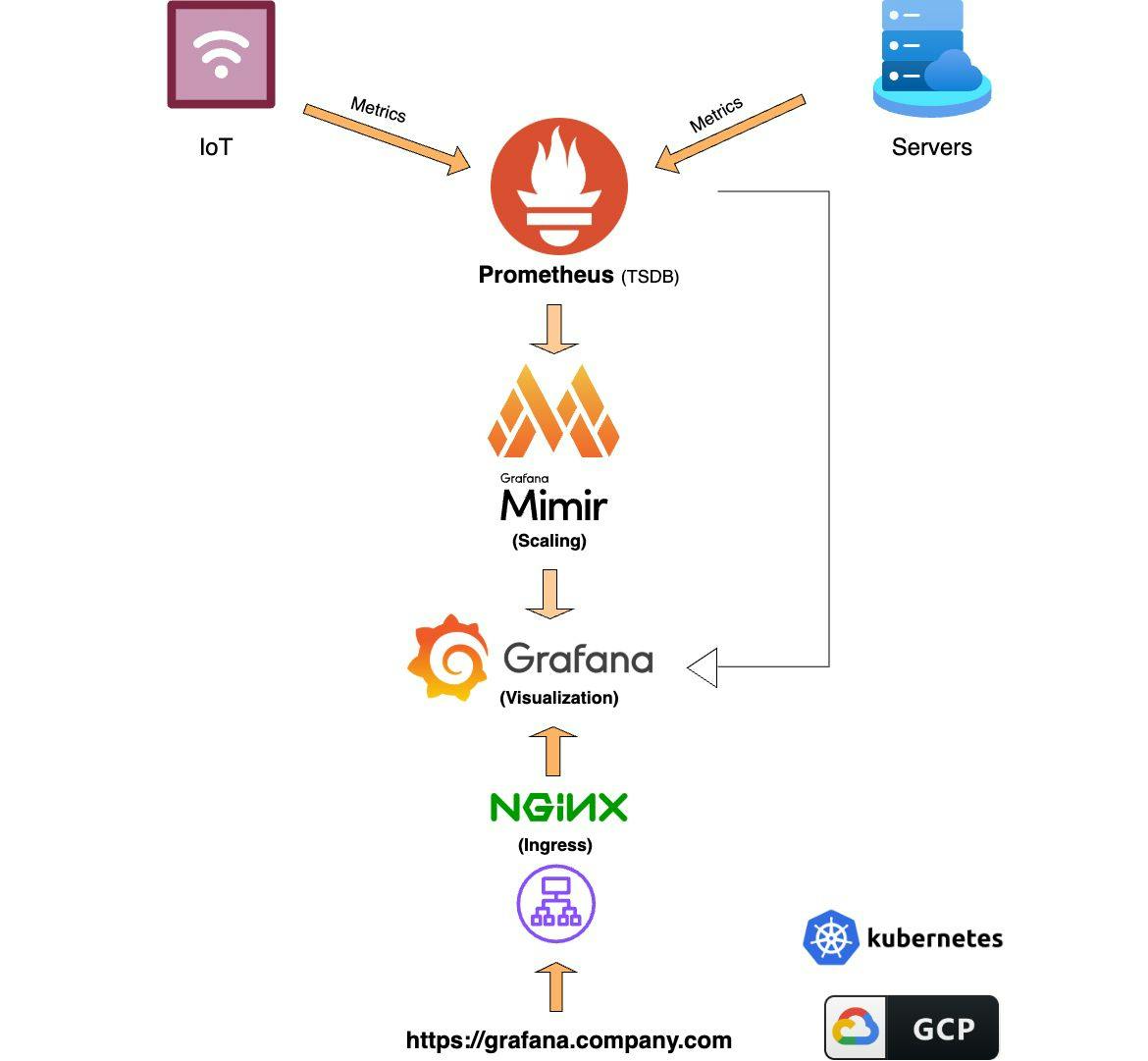
The monitoring basket with my chosen open source contains:
- Prometheus: Time series database (TSDB) that collects and stores metrics from infrastructure and applications.
- Mimir: A scalable, long -term storage program that expands Prometheus by dealing with large amounts of time series.
- Graphana: A rich visualization and tracking tool that displays metrics collected at dashboards and supports warning on the basis of thresholds.
Descriptions and streams of components:
- IoT devices, servers and applications: These are data sources that radiate metrics such as using CPU, memory use and custom application -specific metrics.
- Prometheus (TSDB): Collects and stores time series from Internet devices, servers and applications.
- Grafana Mimir (scaling layer): Expands Prometheus by providing a scalable, durable storage space for large -scale metrics.
- Grafana (visualization): Displays collected metrics at customizable dashboards and graphs and provides warning options.
- NGINX (income controller): Acts as a reverse of Grafana and Prometheus user interfaces and as a safe access point.
- Governor: Orchestra all monitoring chimneys as container services.
- Google Cloud Platform (GCP): Hosts a cluster and supporting infrastructure in the province.


Creating a cluster:
Below is a terraced code to create a private Province in cluster GCP. A similar approach can be used to create private clusters in other cloud environments.
Note: In this setting, we use another project shared network, so appropriate IAM promises and network configurations must be applied.
Github code repo: https://github.com/pradeEp-cadimidi/monitoring
Create a terraced cluster by terracing:
cluster.tf
# google_client_config and kubernetes provider must be explicitly specified like the following.
data "google_client_config" "default" {}
provider "kubernetes" {
host = "
token = data.google_client_config.default.access_token
cluster_ca_certificate = base64decode(module.gke.ca_certificate)
}
# Use selected cluster configuration
module "gke" {
source = "terraform-google-modules/kubernetes-engine/google//modules/beta-private-cluster"
version = "30.2.0"
project_id = var.cluster_config[local.env].project_id
name = var.cluster_config[local.env].name
region = var.cluster_config[local.env].region
zones = var.cluster_config[local.env].zones
network = var.cluster_config[local.env].network
network_project_id = var.cluster_config[local.env].network_project_id
subnetwork = var.cluster_config[local.env].subnetwork
ip_range_pods = "${var.cluster_config[local.env].subnetwork}-pods"
ip_range_services = "${var.cluster_config[local.env].subnetwork}-services"
http_load_balancing = true
enable_l4_ilb_subsetting = true
network_policy = false
horizontal_pod_autoscaling = true
filestore_csi_driver = false
enable_private_endpoint = true
enable_private_nodes = true
remove_default_node_pool = true
master_ipv4_cidr_block = "172.16.0.0/28"
node_pools = [
{
name = "node-pool"
machine_type = var.cluster_config[local.env].machine_type
node_locations = join(",", var.cluster_config[local.env].zones)
min_count = 1
max_count = 1
local_ssd_count = 0
spot = false
disk_size_gb = var.cluster_config[local.env].disk_size_gb
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
enable_gcfs = false
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
service_account = "${google_service_account.gke.email}"
preemptible = false
initial_node_count = 1
autoscaling = false
},
]
node_pools_oauth_scopes = {
all = [
"
"
]
}
cluster_resource_labels = {
environment = local.env
project = var.cluster_config[local.env].project_id,
resource_type = "gke",
resource_name = var.cluster_config[local.env].name
customer = "all"
}
node_pools_labels = {
all = {}
default-node-pool = {
default-node-pool = true
}
}
node_pools_metadata = {
all = {}
default-node-pool = {
node-pool-metadata-custom-value = "node-pool"
}
}
node_pools_taints = {
all = []
default-node-pool = [
{
key = "default-node-pool"
value = true
effect = "PREFER_NO_SCHEDULE"
},
]
}
node_pools_tags = {
all = []
default-node-pool = [
"default-node-pool",
]
}
master_authorized_networks = [
{
cidr_block = var.cluster_config[local.env].subnetwork_allow
display_name = "VPC"
}
]
}
resource "google_compute_subnetwork_iam_member" "network_user_service_account" {
for_each = { for user in var.cluster_config[local.env].network_user : user => user }
project = var.cluster_config[local.env].network_project_id
subnetwork = var.cluster_config[local.env].subnetwork
region = var.cluster_config[local.env].region
role = "roles/compute.networkUser"
member = "serviceAccount:${each.value}"
}
resource "google_project_iam_member" "hostServiceAgentUser_service_account" {
for_each = { for user in var.cluster_config[local.env].hostServiceAgent_user : user => user }
project = var.cluster_config[local.env].network_project_id
member = "serviceAccount:${each.value}"
role = "roles/container.hostServiceAgentUser"
}
resource "google_project_iam_member" "serviceAgent_service_account" {
for_each = { for user in var.cluster_config[local.env].serviceAgent_user : user => user }
project = var.cluster_config[local.env].network_project_id
member = "serviceAccount:${each.value}"
role = "roles/container.serviceAgent"
}
In the Terraform Configuration above, we use the publicly available Google Terraform module terraform-google-modules/kubernetes-engine/google//modules/beta-private-clusterTo. This approach allows us to use a well -maintained, community -supported code, avoiding the need to develop and maintain a complex infrastructure code from scratch.
Below are the rights required for the service accounts used in this terraced configuration:
|
Role |
Why is it needed for GKE |
|---|---|
|
roles/compute.networkuser |
Allow the knots and the load balancers to use the subnet. |
|
roles/container. |
Allow GKE to arrange networking (firewalls, IPs, etc.) in hosts/shared vpc. |
|
roles/container.Serviceagent |
Let the GKE control level manage and use the GCP API necessary. |
Terrform variables:
Below are the variables I used in the Terrform code
variables.tf
variable "cluster_config" {
description = "Cluster configuration per environment"
type = map(object({
project_id = string
name = string
description = string
regional = bool
region = string
zones = list(string)
network = string
subnetwork = string
network_project_id = string
machine_type = string
disk_size_gb = number
subnetwork_allow = string
bucket_names = list(string)
host_project = string
network_user = list(string)
hostServiceAgent_user = list(string)
serviceAgent_user = list(string)
static_ips = list(string)
# Add more attributes as needed
}))
default = {
nonprod-mon = {
project_id = "nonprod-monitoring"
name = "cluster-nonprod"
description = "nonprod cluster"
regional = true
region = "us-central1"
zones = ["us-central1-a", "us-central1-b", "us-central1-c"]
network = "nonprod-vpc"
subnetwork = "nonprod-us-central1-sb01"
subnetwork_allow = "10.226.0.0/22"
network_project_id = "nonprod-networking"
machine_type = "e2-custom-4-10240"
disk_size_gb = "50"
bucket_names = ["mon_blocks_storage", "mon_alertmanager_storage", "mon_ruler_storage"]
host_project = "nonprod-networking"
network_user = ["service-123456789123@container-engine-robot.iam.gserviceaccount.com", "[email protected]"]
hostServiceAgent_user = ["service-123456789123@container-engine-robot.iam.gserviceaccount.com"]
serviceAgent_user = ["service-123456789123@container-engine-robot.iam.gserviceaccount.com"]
static_ips = ["internal-ingress"]
}
prod-mon = {
project_id = "prod-monitoring"
name = "cluster-prod"
description = "prod cluster"
regional = true
region = "us-central1"
zones = ["us-central1-a", "us-central1-b", "us-central1-c"]
network = "prod-vpc"
subnetwork = "prod-us-central1-sb01"
subnetwork_allow = "10.227.0.0/22"
network_project_id = "prod-networking"
machine_type = "n2-custom-4-32768"
disk_size_gb = "100"
bucket_names = ["mon_blocks_storage", "mon_alertmanager_storage", "mon_ruler_storage"]
host_project = "prod-networking"
network_user = ["service-123456789012@container-engine-robot.iam.gserviceaccount.com", "[email protected]"]
hostServiceAgent_user = ["service-123456789012@container-engine-robot.iam.gserviceaccount.com"]
serviceAgent_user = ["service-123456789012@container-engine-robot.iam.gserviceaccount.com"]
static_ips = ["internal-ingress"]
}
}
}
Country of Terrform:
A GCS bucket is used to store national information.
Backend.tf
terraform {
backend "gcs" {
bucket = "environments-state"
prefix = "terraform/state/gke"
}
}
Terraform workspace:
I will use the terraced offices so that you will definitely configure your work space before starting the terracraphorm code. For example, you can set the work space with the following command:
terraform workspace set non-prod
In the Main.Tf file, I defined the work space like this:
Main.tf
locals {
env = terraform.workspace
}
It automatically sets env A local variable corresponding to the current terraced work area (eg, non-prodTo do, prod), allowing the configuration to be dynamically adjusted based on the environment chosen.
Static IPS
To configure DNS records, we need static IP addresses, allowing us to access services using domain names such as prometheus.company.com or grafana.company.com.
Static_ips.tf
data "google_compute_subnetwork" "subnet" {
name = var.cluster_config[local.env].subnetwork
project = var.cluster_config[local.env].network_project_id
region = var.cluster_config[local.env].region
}
resource "google_compute_address" "static_ips" {
for_each = { for ip in var.cluster_config[local.env].static_ips : ip => ip }
name = each.value
address_type = "INTERNAL"
region = var.cluster_config[local.env].region
subnetwork = data.google_compute_subnetwork.subnet.self_link
project = var.cluster_config[local.env].project_id
}
Kuberenes Service Account:
We use a special service account for province nodes to safely manage their rights and follow the best practices.
Service_Account.tf
resource "google_service_account" "gke" {
account_id = "gke-${local.env}"
project = var.cluster_config[local.env].project_id
display_name = "Service account for gke"
}
Mimir GCS buckets:
For Mimir's long -term metric storage space, we need Google Cloud Storage (GCS) buckets, which allows us to effectively scalm and maintain large volume time series data.
gcs_bucket.tf
module "gcs_buckets" {
source = "terraform-google-modules/cloud-storage/google"
version = "~> 5.0"
project_id = var.cluster_config[local.env].project_id
location = "US"
storage_class = "STANDARD"
names = var.cluster_config[local.env].bucket_names
labels = {
environment = local.env
project = var.cluster_config[local.env].project_id
resource_type = "gcs"
customer = "all"
}
}
resource "google_storage_bucket_iam_binding" "buckets" {
for_each = { for bucket in var.cluster_config[local.env].bucket_names : bucket => bucket }
bucket = each.value
role = "roles/storage.objectAdmin"
members = [
"serviceAccount:${google_service_account.gke.email}"
]
depends_on = [module.gcs_buckets]
}
Name premises (in the groinenes):
Once the cluster is set up, create the following name premises
- Promos
- Mimir
- Graphana
- Nginx-singress
Installation (steering wheel diagrams):
Use the steering rooms to install different monitoring software in the respective name rooms. Below is an example of Prometheus, but you can apply this approach to installing other software, such as Grafana, Mimir and NGINX Ingress.
Prometheud-https: //github.com/prometheus-community/helm- charts
Grafana –
Mimir –
Nginx controller-
Helm's commands:
First, add Prometheus Helm's repository and update it:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
Next, pull the Prometheus chart:
helm pull prometheus-community/prometheus --untar
It creates a prometheus/ A catalog in your current job catalog containing the contents of the chart. You can change the default prometheus/values.yaml The file before installing it, allowing you to configure custom configurations such as the administrator password, stability settings and service type.
Now you can install Prometheus with the custom values_prod.yaml File:
helm install prometheus ./prometheus -f prometheus/values_prod.yaml -n monitoring
Similarly, you can install other components:
helm install grafana ./grafana -f grafana/values_prod.yaml -n monitoring
helm install mimir ./mimir -f mimir/values_prod.yaml -f mimir/capped-small.yaml -n mimir
helm install nginx-ingress ./nginx-ingress -f nginx/values_prod.yaml -n ingress
Configuration (values.yaml files):
Entering:
Incoming resources management requires a controller. Just creating an entrance resource has no effect if there is no intruder. Although many intruders, including GKE built -in invasion, have been available for various reasons I have chosen the NGINX invasion controller.
Ingress reveals the http and https routes to the services in the cluster. Traffic routing is controlled by the rules defined in the entry resource.
In this tutorial we use internal IP to reveal the services. Be sure to configure your next helm values.yaml To ensure proper routing and access:
Helmi values.yaml
controller:
service:
internal:
enabled: true
annotations:
# Create internal LB. More information:
# For GKE versions 1.17 and later
networking.gke.io/load-balancer-type: "Internal"
# For earlier versions
# cloud.google.com/load-balancer-type: "Internal"
# Any other annotation can be declared here.
Also submit a static internal IP that you have previously created through terracraphorm loadBalancerIP Field as like:
Helmi values.yaml
loadBalancerIP: "10.x.x.x"
Once the NGINX Ingress controller is installed, it will create a cloud balancer with your cloud service provider (eg GCP). After that, you need to create a suitable destinations to direct traffic, for example Graphana and PrometheusTo.
Ingress's specification includes all the necessary information to configure the charging balancer or proxy. You must add either ingressClassName: nginx Spec Field or Provincees.io/ingress.class: nginx Annotation in your entry resources.
Entrance Resource:
My-In-prod.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: company-ingress
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: grafana.company.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 80
- host: prometheus.company.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-server
port:
number: 80
What does it do:
- In -house: It uses
nginxInstruction for direct traffic of internal services. - Route rules:
grafana.company.com: The traffic is directedgrafana.company.comwill be directedgrafanaService, especially Port 80.prometheus.company.com: The traffic is directedprometheus.company.comwill be directedprometheus-serverService, especially Port 80.
- Handling the road: Both routes use
path: /which means any url that begins/transmitted to the respective services (Grafana or Prometheus).
This configuration ensures that the upcoming domain traffic is aimed at the correct service in your province, based on the host name and the road.
Prometheus:
If you use a tensile model, Prometheus must collect metrics from your targets. To configure this configuration you can set your scraping configuration values.yaml File:
Helmi values.yaml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
If Prometheus requires scaling, it must transmit the metrics for long -term storage. You can configure Prometheus to send a copy of the metrics using Mimir remoteWrite Section in the steering wheel of Prometheus values.yaml File as like:
Helmi values.yaml
remoteWrite:
- url:
The idea of using Mimir is to provide long -term storage to Prometheus metrics. This setting allows you to scal your Prometheus as needed while avoiding the one error point.
I recommend to allow Persistent volumes (PVC) For Prometheus pods. This ensures that your data has not disappeared if remoteWrite It is allowed or in case you use only one instance of Prometheus and you want the problems related to Mimir's meetings. By allowing permanent storage in the steering wheel values.yaml The file ensures that the data is stored by restarting the pod.
Helmi values.yaml
persistentVolume:
## If true, Prometheus server will create/use a Persistent Volume Claim
## If false, use emptyDir
##
enabled: true
accessModes:
- ReadWriteOnce ## Prometheus server data Persistent Volume mount root path
##
mountPath: /data
## Prometheus server data Persistent Volume size
##
size: 500Gi
# storageClass: "-"
storageClass: "persistent-disk-rwo"
Determine the detention time cautiously (--storage.tsdb.retention.time) In the values of Helm.yaml
Helmi values.yaml
## Prometheus data retention period (default if not specified is 15 days)
##
retention: "90d"
Adjust the values according to your needs.
Mimir:
Grafana Mimir It has an open source code, horizontally scalable, multi -tenant time series database and monitoring platform Mimir is fully compatible with Prometheus, which means that it supports the Prometheus data model, the inquiry language (promql) and the scratching mechanism. This may be a background program for holding Prometheus metrics, allowing you to extend beyond what one Prometheus server can handle. Mimir helps to reduce the cost of storing long -term metrics. Mimir is useful
- Save large amounts of time series for a long time.
- Scale Prometheus outside one case.
- Use the isolated storage space with several countries.
- Make sure the scattered troubleshooting meter. Grafana Mimir's architecture is based on the principles of scattered systems using components such as:
- Distributor: Takes and writes data from Prometheus copies or any compatible scraper.
- Iguter: Saves and processes incoming data. The data is temporarily stored in the Ingester until long -term storage is rinsed.
- The gate of the store: Handles from a permanent recording room for data obtaining data and queries.
- Front: Manages the inquiry and routing, ensuring that the queries are distributed in existing Mimir occasions.
- The background program of storage: Mimir uses the GCS storage space in our teaching.
GCS recording rooms that Mimir use mon_blocks_storageTo do, mon_alertmanager_storageand mon_ruler_storagewhich we have configured in our terraced code.
Steering wheel values.yaml File, configure GCS buckets for recording with the necessary mandates to access these GCS storage buckets. This allows Mimir to interact with Google Cloud Storage to save a long-term meter.
Helmi values.yaml
# -- Additional structured values on top of the text based 'mimir.config'. Applied after the text based config is evaluated for templates. Enables adding and modifying YAML elements in the evaulated 'mimir.config'.
# To modify the resulting configuration, either copy and alter 'mimir.config' as a whole or use the 'mimir.structuredConfig' to add and modify certain YAML elements.
structuredConfig:
limits:
out_of_order_time_window: 1h
max_label_names_per_series: 100
common:
storage:
backend: gcs
gcs:
service_account: |
{
"type": "service_account",
"project_id": "prod-monitoring",
"private_key_id": "50885800",
"private_key": "xxxxx-----PRIVATE KEY-----\n",
"client_email": "[email protected]",
"client_id": "108488885",
"auth_uri": "
"token_uri": "
"auth_provider_x509_cert_url": "
"client_x509_cert_url": "
"universe_domain": "googleapis.com"
}
blocks_storage:
backend: gcs
gcs:
bucket_name: mon_blocks_storage
alertmanager_storage:
gcs:
bucket_name: mon_alertmanager_storage
ruler_storage:
gcs:
bucket_name: mon_ruler_storage
Use either by using your requirements capped-small.yaml or capped-large.yaml Values for the Mimir components for determining computing resources. These files allow you to configure the Mimir processor and memory restrictions depending on your implementation scale.
In addition, Mimir has an active community on Slack, where you can get help from other members by setting it in the cluster.
Graphana:
In GraphanaAdd Mimir as a data source for long -term saving metrics. If you use only one Prometheus copy, you can also add a Prometheus data source for the backup. Once the data source is set up, you can visualize the metrics, configure the dashboard and create notifications in Grafanas.
In addition, let Persistent volume requirements (PVC) For Grafana to ensure the loss of data when the pod restarts. It helps to maintain configuration and even pod life cycle changes.
Helmi values.yaml
## Enable persistence using Persistent Volume Claims
## ref:
##
persistence:
type: pvc
enabled: true
storageClassName: persistent-disk-rwo
accessModes:
- ReadWriteOnce
size: 10Gi
Dns
If everything is installed and configured, configure DNS (eg prometheus.company.com or grafana.company.com) to point to a previously created static IP (10.x.x.x) Use of terracraphorm.
After completing this configuration, you should access graphana metrics. From there you can visualize the data, create custom dashboards and set up messages.
For more information on the creation of dashboards and visualization of the data, see Grafanas at https://grafana.com/docs/grafana/latest/dashboards/
Good luck! You are free to contact me in LinkedIn.




