Table
Summary and 1 Introduction
2 related work and 2.1 virtual avatar
2.2 points in the cloud visualization
3 Test Design and 3.1 Setup
3.2 User Presentation
3.3 Methodology
3.4 Virtual environment and 3.5 Description of tasks
3.6 Questionnaires and 3.7 participants
4 Results and Discussion and 4.1 User Preferences
4.2 Fulfillment of the task
4.3 Discussion
5 conclusions and references
4.3 Discussion
According to the questionnaires, we can conclude that the perspective has more impact than the image of the implementation and the performance of the tasks, especially in abstract and the meshes of the mesh. We can also argue that the sense of the point-to-cloud avatar is similar to an abstract avatar, but compared to the performance of the mesh avatar, when the avatar is viewed through a third person's perspective, is significantly better.
The lower feeling of execution identified in the case of 3PP -grid eye can be explained by the universal valley effect. Although the point cloud maps directly into the body of the users, both mesh and abstract performances can be considered simplification, as Microsoft Kinect does not direct all body movements directly (eg detailed arm and head movement). This simplification is accepted in the abstract performance, while its impact is perceived as an error in the mesh avatar.
As for the efficiency of the intended tasks, we found that 1PP had a clear advantage over 3PP. We argue that this result is related to the general preference, which users demonstrate in 1PP, as shown in Table 1. Being a more natural perspective for the user, movement through the environment was faster than comparing 3PP with body experience.
By comparing different avatars, although we found the statistical importance only in the combinations of certain tasks, some considerations can be done. For 1PP, the abstract avatar had a general best performance (for the first task of statistical importance). Being a minimalist presentation than alternatives, less occlusion was seen between the body and the obstacles, with less attention from the proposed goal.
For 3pp, the mesh performance was generally worse performance (for the third task of statistical importance). We associate this result with a lower sense of execution that is explained above in Table 1 and its relationship. It was noticed that it often slows down interaction.
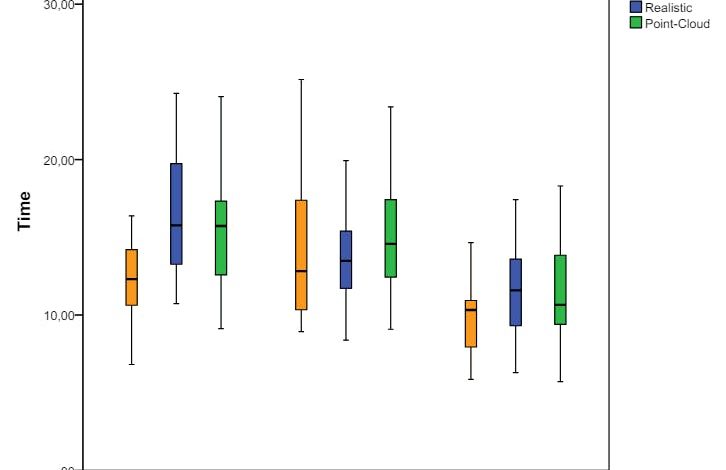
The only task for the successful completion of the proposed tasks was where the 3PP had an overall advantage, the first task where the key factor was spatial awareness. Table 2 shows the results, with a point-to-cloud presentation of the presentation is the best performer, the lowest average number and the number of participants, who completed the task without collisions (the statistical importance was only found compared to the mesh avatar).
For the second task, 1PP had an advantage (the statistical importance found for the mesh and point-to-point avatar) except



A point-cloud presentation, which had worse performance in both perspectives. We attribute the fact that this performance is visually richer. While it helps with the sense of incarnation, occlusions create naturally rendered splits or clothing (pants, shoes) both 3PP and 1PP and body parts (breasts, stomach) 1PP.
The third task was strongly influenced by the illegal assessment of the height of the obstacle. This may explain the fact that no statistical significance was found between any representation/perspective, except for the abstract avatar, which works better in 1PP. Users would overestimate how low they need to go, most of the time they need to go. When analyzing the questionnaires, users reported a 1PP for this task. This can be associated with the fact that the 3pp virtual head is not exactly where the user's actual head is. The rating of the obstacle height is more complex from this perspective and the user balance is more influenced by the use of a camera in 3PP, as reducing your body can affect your sense of balance.
Finally, 1PP had an advantage in the fourth task (Table 3). For this perspective, both the point cloud and the abstract avatars were in front of the mesh in front of the Avatar (with statistical importance). For the 3pp, point-to-cloud avatars had the worst performance (statistical importance found). We again attribute the occlusions created by users' body and clothing, which could inhibit the exact visualization of the trajectories of the bullets.
We noticed that the most “realistic” combination (1PP point-cloud presentation) was the fastest in time, while many obstacles were hit. This result may indicate that the user feels more confident in assessing the distance of this design, leading to a greater number of errors in avoiding obstacles.