Ties
Summary and 1 Introduction
2 COOGEN: representing common sense structures with code and 2.1 Conversion (t, g) in python code
2.2 Invitation to a few shots to generate G
3 evaluation and 3.1 Experimental configuration
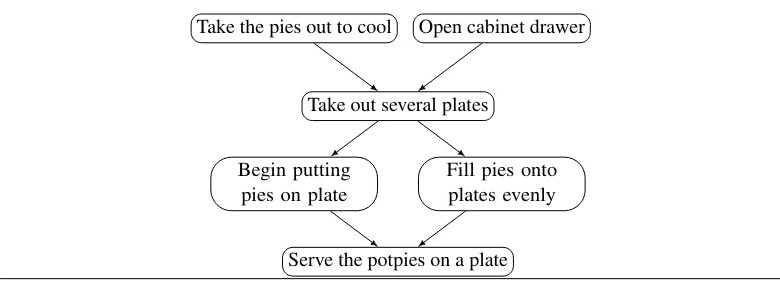
3.2 Script generation: proscript
3.3 Monitoring of the state of the entity: Propara
3.4 Generation of argument graphics: Explagraphs
4 analysis
5 related work
6 Conclusion, thanks, limitations and references
Size estimates of the models a few strokes
B Dynamic prompt creation
C Human evaluation
D Statistics of the data set
E Splemates output
In invites
G Design a python class for a structured task
H Impact of the size of the model
I Variation of prompts
Structured common sense reasoning using LLMS The existing methods of a structured common sense generation generally flatten outing graphics like ropes (Madaan and Yang, 2021; Madaan et al., 2021a; Sakaguchi et al., 2021). Consequently, these methods have trouble with the generation of well -formed outings (Sakaguchi et al., 2021; Madaan et al., 2021b). On the other hand, we approach the problem of generation structured by (1) translating the task into Python code, and (2) the generation of code using models of large code generation.
Representation of the code for the reasoning of procedural knowledge Programs intrinsically code rich structures and can effectively represent task procedures. Existing work takes advantage of the control flows, nested functions and API calls from programming language such as Python to control agents located in the embodied environment (Sun et al., 2019; Zhou et al., 2022; Singh et al., 2022). In this work, we go beyond these procedural tasks and show the effectiveness of the use of code LDMS on wider structured tasks of common sense.
Adapt the code of code for reasoning While CodeGeneration (Code-LLMS) models are becoming more and more popular, there is an increasing interest in adapting them to wide range reasoning tasks. Wu et al. (2022) Use the codex and palm (Chowdhery et al., 2022) to convert mathematical declarations written in natural language into a formal structure which can be used for the promotional theorems, with moderate success. The task is difficult, because it involves understanding the concepts used in the theorem (for example, set of real numbers) and the complex relationship between them. Our work is similar in mind to Wu et al. (2022), and seeks to take advantage of the double capacities of LLMS of code for text and symbolic reasoning. However, differently from their work, we conclude the gap between the pre-training data and our tasks by translating our output into Python code. As our experiences show, this step is crucial to surpass text models only and refined. To our knowledge, our work is the first to transform a reasoning problem into a natural language in code to successfully exploit code generation methods.
Symbolic reasoning using LLMS The use of programming languages such as Lisp (Tanimoto, 1987) and Prolog (Colmerauer and Roussel, 1996) to treat natural language has a long history in AI. However, recent progress in large languages have enabled the need for specialized symbolic treatment methods. COBBE et al. (2021) and Chowdhery et al. (2022) Treat the resolution of intermediate level algebra problems using large -language models in a configuration with a few strokes. These problems require a model to understand the order in which a set of operations must be carried out on symbols (generally small). On the other hand, structured common sense reasoning requires wider information than that provided in the prompt, while using the structural generation capacities of models to effectively generate production. Thus, the tasks of our work push a model to use both its reasoning and symbolic manipulation capacities.
Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, United States ([email protected]));
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]));
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]));
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]));
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]).




