One of the largest challenges in modern systems is to operate on a large scale. As the systems increase, they must meet growing high availability, scalability and resilience requests. To meet these needs, we are counting on techniques such as scaling, cache and horizontal and vertical redundancy. However, the processing of a service as a single unit introduces risks – any software or operational error can reduce the entire system, which can be disastrous. In this article, we explore architecture based on cells, a design approach that improves resilience, stimulates availability and allows practically unlimited scalability.
Why is the adoption of cell-based architecture important?
By adopting cell architecture in distributed systems, you will appreciate it:
-
High availability: Cells improve the availability of the system because they reduce the risk of failure. A system with N cells will have no more failure events, but each with 1 / nth of the impact.
-
High: Cell -based architecture allows horizontal scaling, allowing services to develop rather than more. This makes it particularly effective in scenarios where the limits of quotas on dependent services become a bottleneck.
-
System resilience: Cells are autonomous images of service, so any problem or service failure in one cell has no impact on another cell. This design also helps to increase the average time between failures and shorten the average recovery time.
-
Safer deployment: Cells promote deployments in phase and reduce the breath of breath of problematic deployments. The deployment of services is safer when we use a phase deployment approach.
What is cell-based architecture?
In cell -based architecture, a service is made up of two things:
-
Many cells, where each cell has the same image of your service, a complete replica of your service with all dependencies, and
-
A routing layer to transport traffic to a dedicated cell. A customer request will go to a dedicated cell according to the routing algorithm or the mapping structure. You will find below an example to help illustrate this.
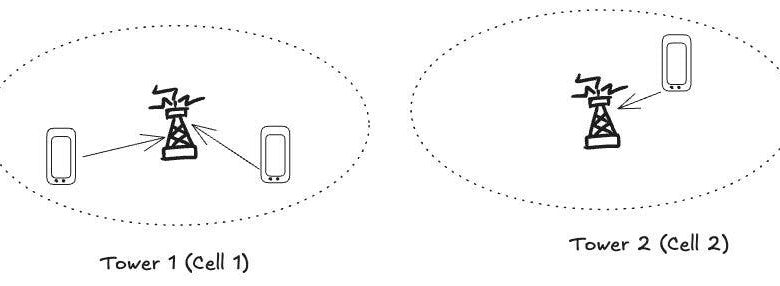
Consider your mobile device connected to a mobile tower. This tower serves devices in a limited beach. If another tower works badly, it does not have an impact on your mobile service because each round is a dedicated cell. In addition, if your turn faces a problem like a breakdown, the mobile device will reconnect to another tower nearby. This guarantees uninterrupted service, leading to better availability of services and resilience.
Cell -based architecture in the software operates similarly. They serve limited users, reduce the degradation of the service and contribute to a high election. The diagram below represents a real example of cell architecture.



Cell -based architecture design
As discussed in the previous section, a service includes:
-
many cells and
-
Routing layers.
The design of cell architecture seems quite simple. However, many factors make it difficult and require the technique judiciously. In the real world, most services are not designed on the basis of creation cells. They evolve as they grow up, and at some point, when they cannot be more scale, we adopt cell architecture. It is always great to incorporate this approach from the first day of the design of your service, which prevents us from scaling problems and re -chitecture challenges such as migration, back compatibility and the operation of the service. You will find below a high level design of a cellular architecture of a service.


Let us examine the constituent elements of cells based on cells.
Cells
A cell is an instance of your service which includes:
-
All dependencies and their interconnections.
-
Storage – It has a maximum fixed capacity, for example, it can be used as much as possible of 1000 customers. To meet increased demand, just run a new cell.
The diagram below shows a service with all dependencies (and without any cell). It is always an evolutionary service using a horizontal / vertical scale, chatting, etc.


You will find below the cell architecture of the same service. We have the same service replica in two cells (accounts) with all dependencies. A request to the service is sent to one of the cells according to the routing algorithm.


Routing layer
This is a thin layer that manages demand routing. He maps the customer's request to a dedicated cell. For example, you can have a modulo operation on the demand value of the request to route a request. Usually we keep this layer as light as possible so that we do not cause any latency and failure in processing demand.
Routing key and algorithms
The routing key is the dimension on which the cells are allocated. It can be userId,, accountId Or a hash of a combination of fields in demand. It is recommended to use well distributed attributes for routing keys.
Routing algorithms can be as simple as a modulo operation to a database search. Some of the algorithms you can use are:
- Modulo cartography: Use a modular operator to map the keys to a cell.
int getCell(int routingKey) {
return routingKey / getNumberOfCell();
}
int getCell(int routingKey) {
return consistentHash(routingKey, getNumberOfCell());
}
- Table mapping: Use a mapping table that maps the routing keys to the cells.


The most common approaches are the hash and mapping of the table. The table mapping allows you to replace a card. However, it is resolved with the challenge of refreshing the card as and when the number of cells changes in our architecture. We can also use a cell routing algorithm to devote a cell to a large customer or test environment to solve the noisy neighbor's problem.
Cell migration
In certain situations, we may have to do a cell migration if our services are with state. It is always advisable to render your service without state to avoid this situation; However, if it is inevitable, be careful in cell migration to avoid any disruption of the service. Migration implies three stages: –
-
Move data from one cell to another
-
move traffic to the new cell and
-
Cleaning the older cell data.
We start by copying the data from one cell to another cell, then we update routing logic to move traffic. Once the traffic is completely moved to the new CEL, L, we clean the data of the older cell.
Tips and tips
- Design stateless service components. Stateless services are easy to maintain in cell architecture. A service with state requires general cell migration costs.
- Configure the cells according to regional traffic. You don't need to have the same number of cells in each. For example, you can have 10 cells in the American region and 5 cells in Asia depending on demand.
- Carefully choose Routingkey attributes.
- Incorporate the cells of day 1 in your design.
- Define the component as light as possible for the routing layer.
- Conceive carefully for cell migration.
Conclusion
Cell -based architecture is a powerful and proven architecture to make the systems more resilient and very scalable. This approach guarantees scalability even if the dependent service quota is a limiting factor. It is a simple model, but requires a careful service design to operate independently in cells. I will present a case study of the adoption of cell architecture to solve the problem of scaling after launching and executed the production service for 6 months.