Authors:
(1) Anthi Papadopoulou, Language Technology Group, University of Oslo, Gaustadalleen 23b, 0373 Oslo, Norway and corresponding author ([email protected]));
(2) Pierre Lison, Norwegian Computing Center, Gaustadalleen 23a, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23a, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, University of Oslo, Gaustadalleen 23b, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway.
Ties
Summary and 1 Introduction
2 context
2.1 Definitions
2.2 NLP approaches
2.3 Data edition preserving confidentiality
2.4 Differential confidentiality
3 data sets and 3.1 Benchmark Anonymization of the text (tab)
3.2 Wikipedia biographies
4 Recognize private life entities
4.1 Wikidata properties
4.2 Silver corpus and fine model adjustment
4.3 Evaluation
4.4 Disagreement labeled
4.5 Various semantic type
5 risk of confidentiality indicators
5.1 LLM probabilities
5.2 SPAN classification
5.3 Disturbances
5.4 Sequences labeling and 5.5 Web search
6 Analysis of confidentiality risk indicators and 6.1 evaluation metrics
6.2 Experimental results and 6.3 discussion
6.4 Combination of risk indicators
7 conclusions and future work
Statements
References
Annexes
A. Wikidata human properties
B. Training parameters for recognition of entities
C. Label Agreement
D. LLM probabilities: Basic models
E. Size and performance of the training
F. Disturbance thresholds
Abstract
Text disinfection is the task of dreading a document to mask all the occurrences of personal identifiers (direct or indirect), in order to hide the identity of the referred individual. In this article, we consider a two -step approach to text disinfection and provide a detailed analysis of its empirical performance on two recently published data sets: the text reference (Pilan et al., 2022) and a collection of Wikipedia biographies (Papadopoulou et al., 2022). The text disinfection process begins with a confidentiality -focused entity recognition which seeks to determine the text spans expressing identifiable personal information. This confidentiality -focused entity recognition is formed by combining a standard entity recognition model with a reduced repertoire populated by terms related to the extracted from Wikidata. The second step in the text disinfection process consists in assessing the risk of confidentiality associated with each range of text detected, isolated or in combination with other text racks. We present five distinct indicators of the risk of reidentification, respectively on the basis of the probabilities of the language model, the classification of text scope, the labeling of sequences, disturbances and web research. We provide a contrastive analysis of each confidentiality indicator and highlight their advantages and limits, in particular in relation to the labeled data available.
1 introduction
The volume of text data available online increases permanently and constitutes an essential resource for the development of large languages models (LLM). This trend has important implications for confidentiality. Most text documents indeed contain personally identifiable information (PII) in one form or another-that is to say information which can lead directly or indirectly to the identification of a human individual. PII can be divided into two main categories (Elliot et al., 2016):
Direct identifiers, which is information that can directly and irrevocably identify an individual. This includes for example the name of a person, the passport number, the email address, the telephone number, the username or the reception address.
Almost identifiers, Also called indirect identifiers, who are not sufficient in itself to distinguish an individual, but can do so when combined with other almost identifying. Examples of almost identifying people include nationality, occupation, sex, workplace or the person's date of birth. A well-known illustration of the risk of confidentiality posed by quasi-identifiers comes from Golle (2006) which showed that between 63% and 78% of the American population could be identified in a unique way by simply combining their gender, their date of birth and their postal code.
Although some PII can be mild (if the text transmits, for example trivial or public information), it is far from always the case. Documents such as judicial judgments, medical records or interactions with social services are often very sensitive, and their disclosure can have catastrophic consequences for those involved. The modification of these documents to hide the identity of these individuals is therefore often desirable both in an ethical and legal perspective. This is precisely the objective of text disinfection (Chakaravarthy et al., 2008; Sanchez and Batet, 2016; Lison et al., 2021).
In this article, we present a two -step approach to the problem of text disinfection and provide a detailed analysis of its performance, based on two recently published data sets (Pil´an et al., 2022; Papadopoulou et al., 2022). The approach first aims to detect text racks that transmit personal information, using a neuronal sequence labeling model that combines recognition of named entities (NER) with a directory. The Gazetteer is built by deducting from Wikidata a set of properties generally used to characterize human individuals, such as “position” Or “mode of death», And crossing the knowledge graph to extract all possible values for these properties. In the second step, the risk of confidentiality of the text racks detected is assessed according to various indicators. Finally, text spans that are deemed to be an unacceptable risk according to these indicators are masked. An overview of the approach is illustrated in Figure 1.
The document makes the following four contributions:
-
Confidentiality-focused entity recognition to detect PII information beyond the named entities, using large lists of terms related to the extracted from Wikidata, extending the previous work of Papadopoulou et al. (2022).
-
A quantitative and qualitative assessment of the performance of this recognition of a privacy entity for various types of PII.
-
The development of five risk of confidentiality indicators, based on LLM probabilities, SPAN classification, disturbances, sequence labeling and web research.


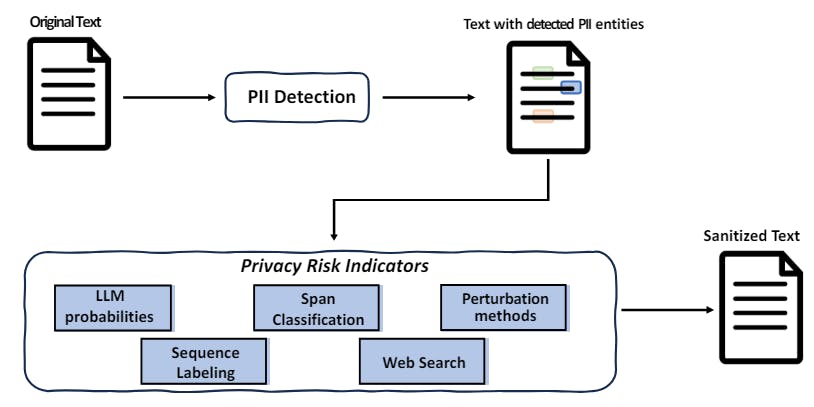
4. A comparative analysis of these risk of confidentiality indicators, both in isolation and in combination, on the two aforementioned data sets.
The document consists of the following sections. Section 2 provides a general context on data confidentiality and text disinfection. We then describe in section 3 the two sets of data annotated for text disinfection used for the empirical analysis of this article. In section 4, we present, assess and discuss recognition of entity focused on privacy for the detection task of PII in text documents. We present the set of five risk of confidentiality indicators in section 5. The empirical performance of these indicators on the two data sets are then analyzed in section 6. We conclude in section 7.




