
Ties
Summary and 1 Introduction
2 COOGEN: representing common sense structures with code and 2.1 Conversion (t, g) in python code
2.2 Invitation to a few shots to generate G
3 evaluation and 3.1 Experimental configuration
3.2 Script generation: proscript
3.3 Monitoring of the state of the entity: Propara
3.4 Generation of argument graphics: Explagraphs
4 analysis
5 related work
6 Conclusion, thanks, limitations and references
Size estimates of the models a few strokes
B Dynamic prompt creation
C Human evaluation
D Statistics of the data set
E Splemates output
In invites
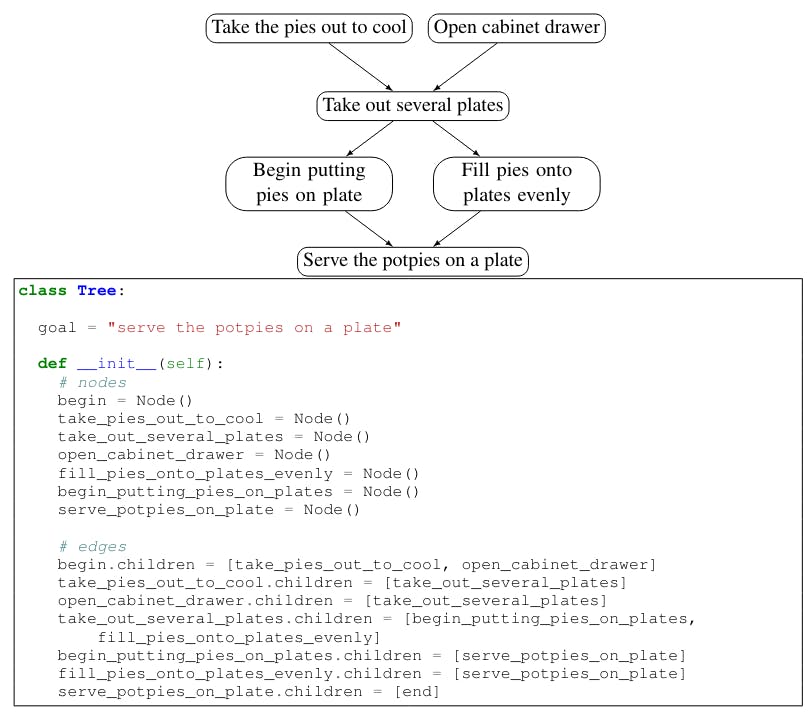
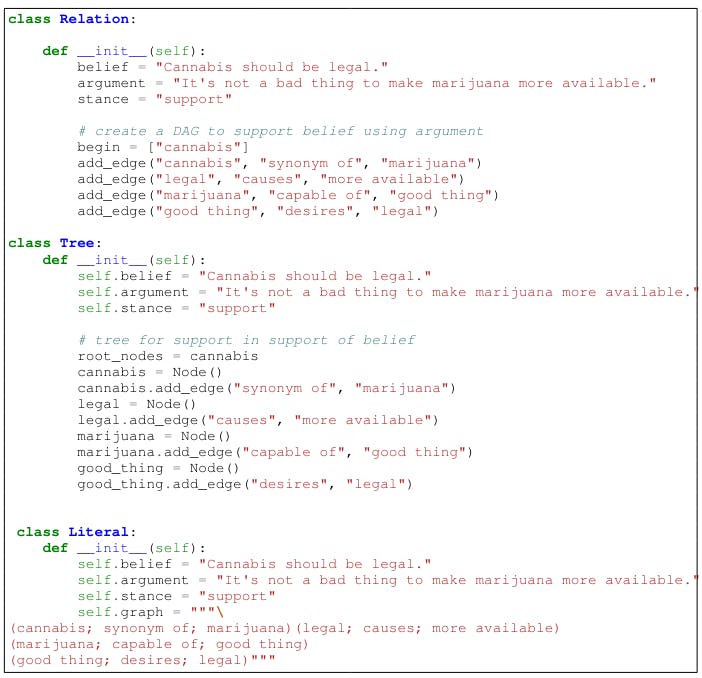
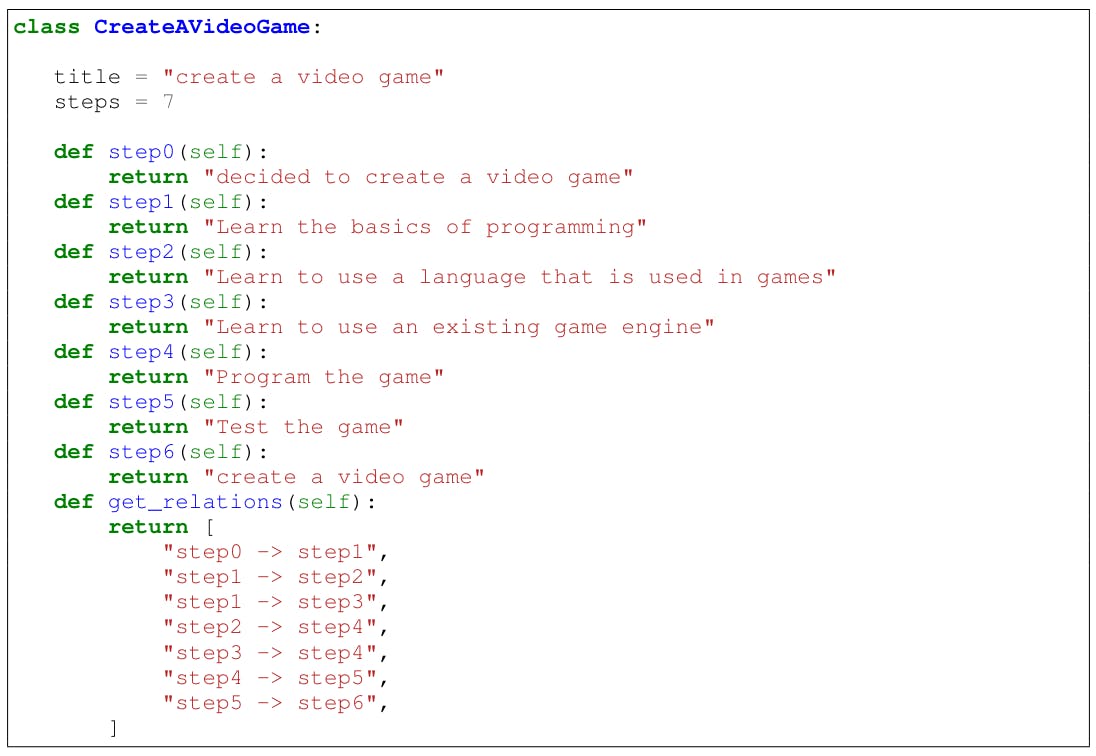
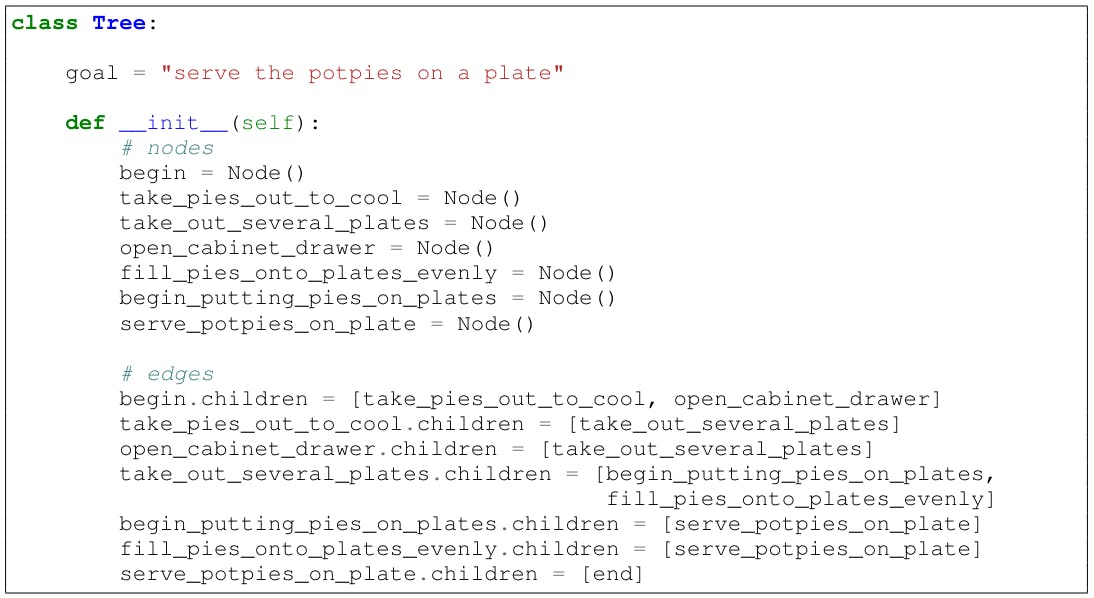
G Design a python class for a structured task
H Impact of the size of the model
I Variation of prompts
G Design a python class for a structured task
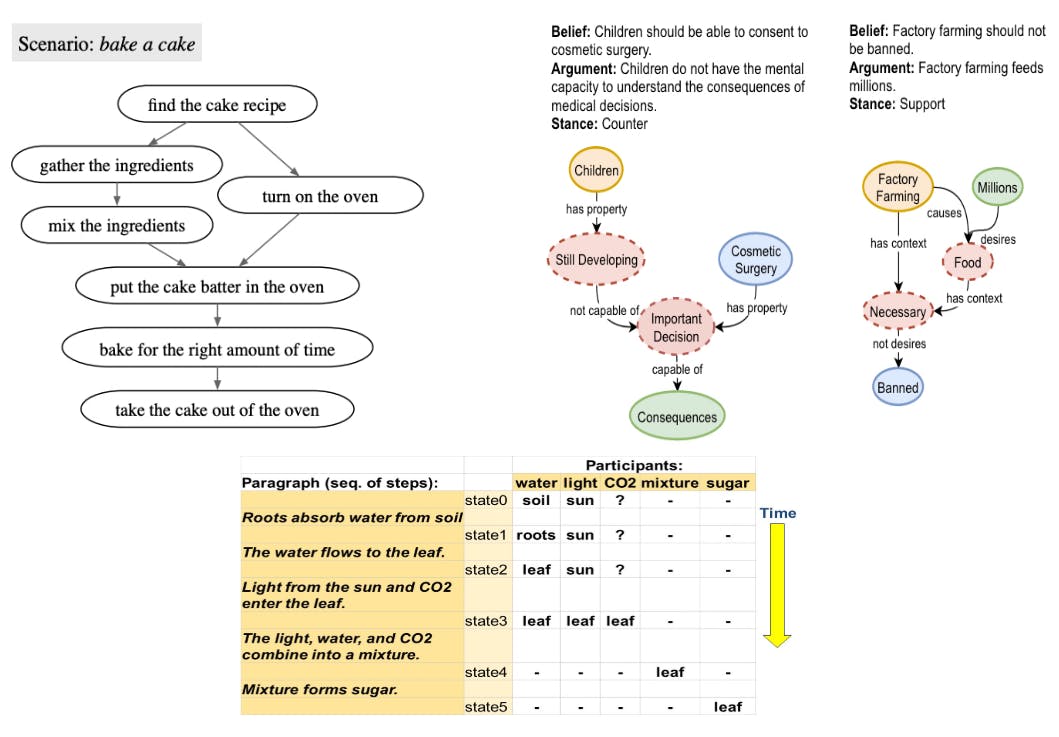
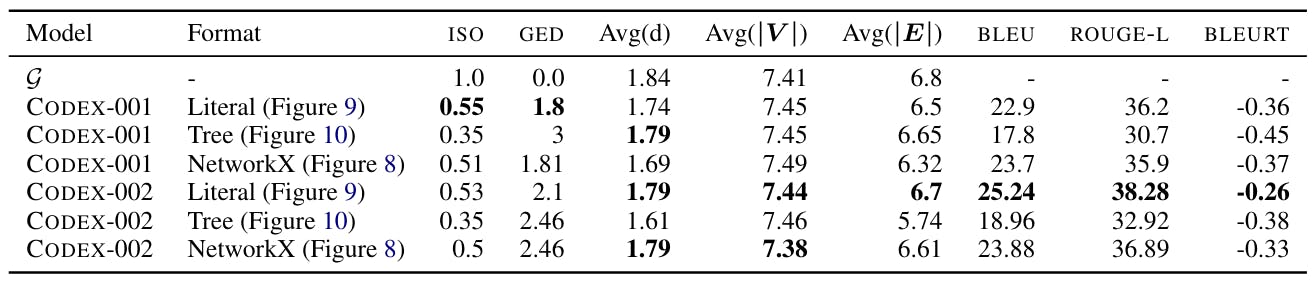
Figure 7 shows three different conceptions for the explanors. For proscribed, the different formats include the representation of proscribed as a networks[8] Class (8), Class 9 in the form of a point and as an arbre (10).
H Impact of the size of the model
The Codex model published by Openai is available in two versions[9]: Code-Davinci-001 and Code-Davinci-002. Although the exact sizes of the models are unknown because of their owner nature, the OPENAI API indicates that the Davavinci-002 code is the most capable codex model tables 16 and ?? Compare Coogen + Code-Davinci-001 with Coogen + Code-Davinci-002. Note that Code-Davinci-001 and Code-Davinci-002 can adapt to 4000 tokens, so that the number of examples in the context was identical for the two parameters. The results show that for the identical prompts, Coogen + Code-Davinci-002 largely surpasses Coogen + Code-Davinci-001, showing the importance of having a better model of underlying code generation.





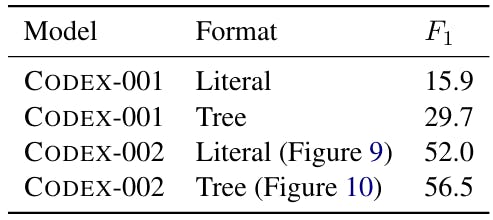
The size of the model in relation to the sensitivity to the invite of Table 14 shows the performance of Codex-001 (smaller) and Codex-002 (larger, also see Appendix A) on identical prompts. Our experiences show that as the size of the model increases, the sensitivity of the model on rapid design could gradually become easier.
I Variation of prompts
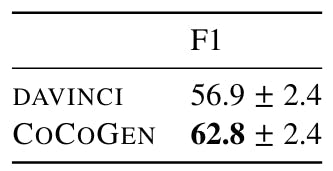
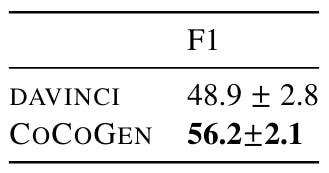
We execute each experience with 4 different random seeds, where random seeds decide the order of examples in the invite. We find a minimum variance between the executions using different fixed prompts between 3 analyzes. In addition, as paintings 18, 19, 20 and 21 show, all cocogen improvements on Davinci are statistically (value p <0.001).


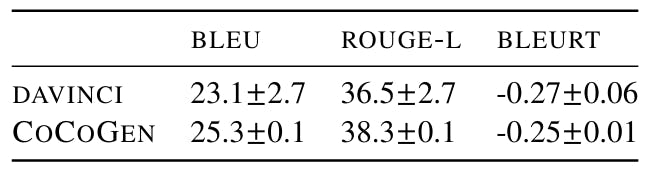












[9] In June 2022
Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, United States ([email protected]));
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]));
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]));
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]));
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]).




