
The growth of company data has changed data technology through significant changes and new paradigms. Modern technological advances such as cloud data processing, artificial intelligence, non-server computing and scattered computer systems contribute to the main amendments in the field. The data technology turns out to be an exciting area that naturally exists. This domain does not have a standard company framework because it contains numerous different data sources.
Ofdata Engineering in the field stands through large language models (LLMS) with a new alarm wave. The combination of Gen AI technology with large language models makes data technique, providing important progress progress and improving operational efficiency.
LLMs may work in scenarios that lack true visibility in data as they deal with traditional data projects with controlled and known data sources. What ways can these AI systems simplify data engineers' work processes?
The article explores the methods through which LLM can improve traditional data technique tasks in the company settings.
Understanding large language models
Large language models (LLM) represent artificial intelligence systems that learn human language from massive text databases to perform human language understanding and generational tasks. Openai GPT-4 and Google's Palm demonstrate the latest border model technology.
LLMs need billions of parameters with contexts to which organizations can train them. The system learns and predicts the following coherent contextual word or statement or passing through it. Users can ask LLMs to perform different tasks such as essay writing, language translation, e -mailing, codes generation and human conversations.
Architecture of Transformer Models
The transformer architecture acts as a basic structural element consisting of large language models. Through successive data learning, the nerve network identifies the context by observing the sequences of both sentences as well as video and video and video data. Transformer models allow for quick and accurate translation of text with speech processing in almost real time.
Transformer architecture consists of the following basic components:
- The user input with administration is the starting point for the model processing. The attachments process the words into numerical performances that machine learning models understand.
- Position coding has made the positions of the words in the input sequences as the input of the transformer into numerical sequences. The coder works as a nerve network that analyzes the input text to obtain hidden states that contain both meaning and contextual information.
- The decoder uses the previous words in the phrase to determine the following words at its output. The decoder receives the output stream that has been properly shifted to allow the use of the previous words.
- The output sequence passes through the decoder to obtain an output sequence based on a coded input sequence.
Below is a simplified diagram of a transformer model:


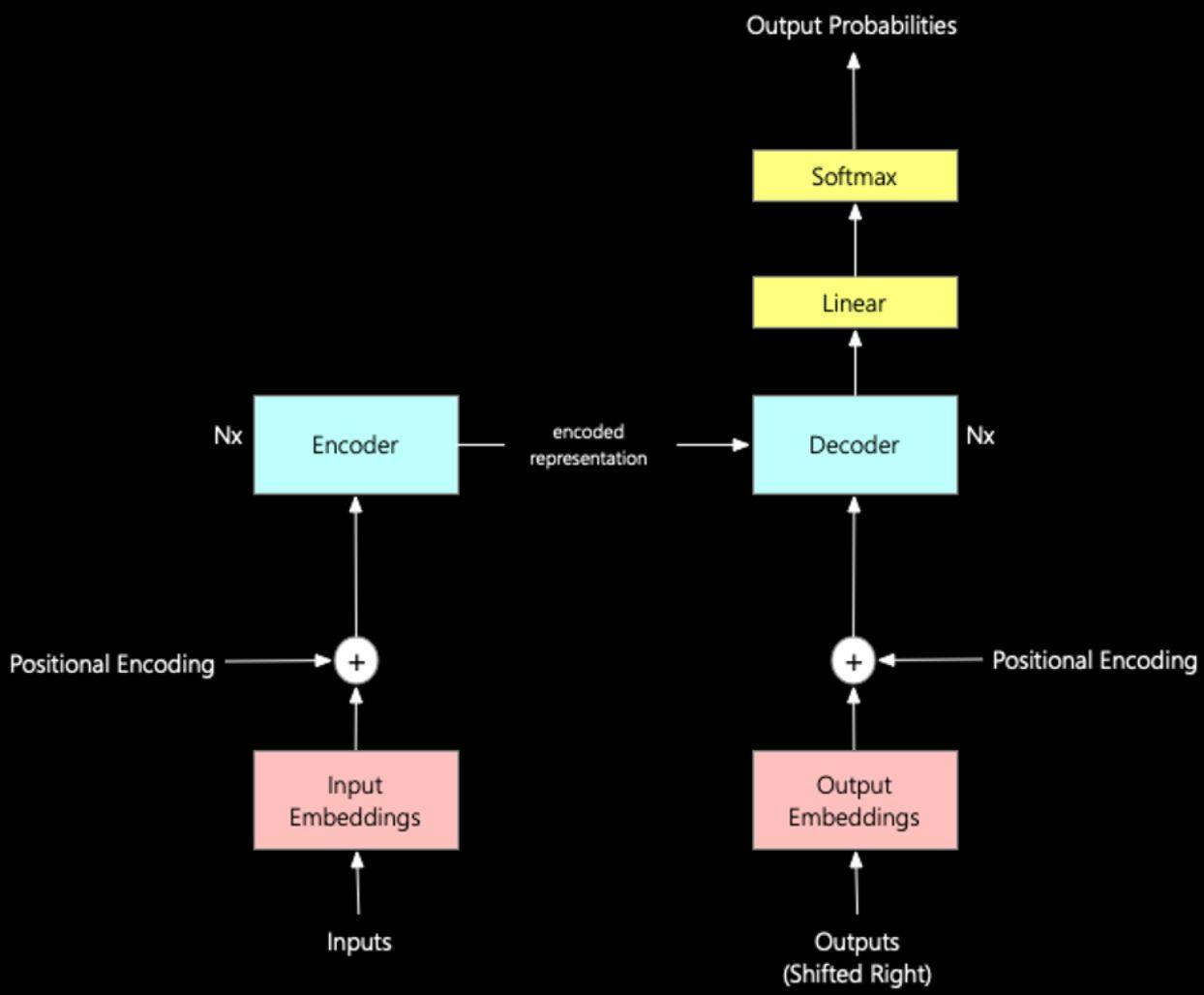
Diagram of the transformer model (source)
LLM applications in data technology
LLMs increase the performance of data technology with the needs of the basic data projects, together with advanced needs for data teams in developing the framework.
LLMS accelerates data technique research
LLM is a tool that accelerates engineering operations. Data technique research is an important basic element of its basic operations. The implementation of new solutions to read documented uses and various papers is an important challenge for data engineers and data scientists.
The users now have the opportunity to use the LLM to solve this problem. This technology offers a number of architectures that data engineers can use. The selected architecture receives support from LLM by generating step-by-step instructions.
Pre -processing and cleaning of data
Organizations can be applied to the management of non -structured data systems. During the data technology, users must clean undue untreated data before properly available before providing a proper query. The preliminary processing operation creates easily understandable metrics for stakeholders with decision -makers.
Data engineers can apply LLMS for their work. The user requires a comparison of the product between different sellers. Development of a custom parser using LLM technology allows the analysis of the product names, features and prices found on E-Commerce websites. The GPT tool tool allows users to do a quick deep research through the withdrawal of websites. The tool is looking for reliable sources and sorts the results of the study before the addition of references.
Modern opportunities for LLM extend valuable support for a number of data technology applications, although they cannot meet all your requirements. This technology creates results that are not always accurate but accelerates and changes modern data processing.
Below is a sample script that uses Python and GPT-3 data to clean:
import openai
def clean_data(data):
prompt = f “Clean the following data: {data}”
response = openai.Completion.create(
engine= “davinci-codex”,
prompt=prompt,
max_tokens=100
)
cleaned_data = response.choices[0].text.strip()
return cleaned_data
# Sample data
data = "Name:John,Doe Age:30\nName:Jane,Smith Age:25"
cleaned_data = clean_data(data)
print(cleaned_data)
Integration of data
Business operations today create numerous diverse data sources that continue to grow. The process of joining two data collections sometimes provides valuable new knowledge. The process of improving such complex data sets causes significant difficulties for data engineers and analysts.
The ability of organizations to synthesize and integrate data sets quickly through LLMS provides them with flexibility in their operations. This technology offers two functions: it detects missing values for adding knowledge and detects additional data sources for enrichment. This ability opens the power of analyzing data analysis.
Improvement of the data review
LLM has the ability to improve data. The 3000 user profile data set, the field field of which allows the free user input, changes the system two types of user addresses according to the states and cities, such as California and Los Angeles. The data engineer must create the right structure before starting work. The engineer can upload the data set to LLM, which can be connected to connect the data and add an overview. LLM adopts instructions to identify the values of the location containing city names and then makes these values into appropriate status.
Detecting anomalies in data
Companies can use LLM to detect mismatches and deviations with missing values and errors. This technology includes an understanding of a built -in context that allows it to identify and improve data problems. Through this capability, avoid spending organizations manually to control the time and resources in dealing with large data sets.
Using LLMS to obtain hidden data
Large data sets receive specific treatment through LLM, which allows data scientists, engineers and business analysts to be clarified. This technology performs data mining functions at a human level that is similar to a user but at a faster pace. LLMs show the context to understand important conclusions through their opportunities. This technology can be obtained from several formats, including text, videos and audio files.
Automation of tasks
LLMs offer data engineers the opportunity to automate routine operations. This technology allows users to create automated scripts that use recurrent data conversion tasks using natural language descriptions. Great thoughts can focus on creating a sophisticated logic, as AI does monotonous and annoying work.
Future for LLMS for data technique
LLMs bring a modern data technology environment that develops rapidly, with several performance. These AI admirations change the data processing revolution, accelerating workflows, improving data quality and automating tasks. Organizations can integrate this technology into their data analysis action plans to create a more innovative and flexible data -based future.
LLMs show a number of possible advantages of data technology, but they provide certain restrictions. The growing demand for LLM and business requirements can increase the cost of this technology. Free tools provide users with the transformation of their data technique requirements, while they can access the open source code. The selected users of free tools are facing restrictions on how much their systems understand. The processing of data technology applications with extensive context in Windows requires advanced LLMS, which also consume larger resources.
Developing large language models remains in its early stages, so human supervision and control are still essential for them. LLM generated outputs may include inaccurate or biased information that forces data engineers to use their domain knowledge and critical thinking skills to control LLM outputs and to maintain data pipeline control.
The initial limited use of large language models in data technology has a significant impact as AI continues to spread throughout the industries.



