Authors:
(1) Anthi Papadopoulou, Language Technology Group, Oslo University, Gaudadalleen 23b, 0373 Oslo, Norway and corresponding author ([email protected]);
(2) Pierre Lison, Norwegian Calculation Center, Gaudadalleen 23a, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian computing center, Gaudadalleen 23a, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, Oslo University, Gaudadalleen 23b, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, Oslo University, Gaudadalleen 23b, 0373 Oslo, Norway.
Table
Summary and 1 Introduction
2
2.1 Definitions
2.2 NLP approaches
2.3 Disclosure of Privacy Maintain Data
2.4 Difference Privacy
3 Data sets and 3.1 Text anonymized benchmark (tab)
3.2 Wikipedia biographies
4 Privacy -oriented item recognition
4.1 Wikida properties
4.2 Silver Corpus and Model Fine Tuning
4.3 Evaluation
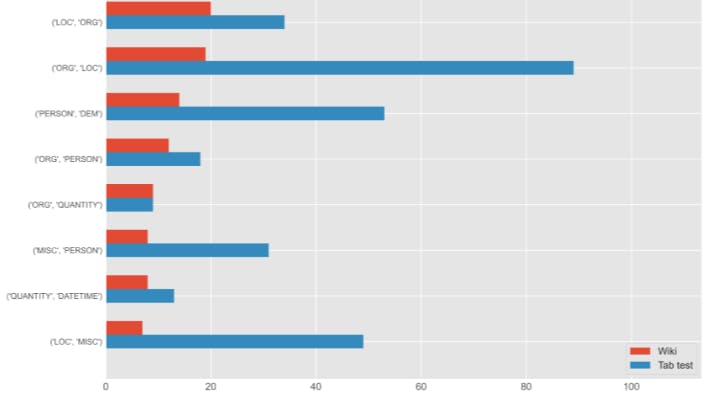
4.4 Tag Disagreements
4.5 MISC Semantic Type
5 Privacy risk indicators
5.1 LLM probabilities
5.2 Classification
5.3 PERTURBATIONS
5.4 Song Signing and 5.5 Web Search
6 Analysis of Privacy Risk and 6.1 Assessment Metrics Analysis
6.2 Experimental results and 6.3 discussion
6.4 A combination of risk indicators
7 conclusions and future work
Declarations
References
Extras
A. Wikida human qualities
B. The training parameters of the entity of the unit
C. Tag contract
D. LLM probabilities: basic models
E. The size and performance of training
F. Perturbation thresholds
2.3 Disclosure of Privacy Maintain Data
PPDP approaches to disinfecting the text are based on the Privacy Model, which specifies the official conditions to meet the data to ensure that the data is shared without damaging the privacy of registered persons. The most striking privacy model is k-anonymity (Samarati and Sweeney, 1998), which requires an individual/unit to be indistinguishable from other individuals/units. This model was then adapted to text data with approaches such as K-Säht (Chakaravarthy et al., 2008) and K-Consfiscus (Cumby and Ghani, 2011).
The T-plum (Anandan et al., 2012) follows a similar approach using personal information that has already been identified and ensuring that they are sufficiently generalized to ensure that at least T-documents can be mapped with edited text. Sanchez and Batet (2016) provide C-sitized, based on information theoretical approach, which calculates the dotted mutual information (using the number of web data) between a person or unit and a unit between the unit. The concepts whose mutual information reaches the threshold is then masked.
k-Adonymity was also used by Papadopoulou et al. (2022) with NLP-based approaches where the optimal set of masking decisions was found on the basis of the assault on the attacker k-anonymity.
Finally, Manzanares-Salor and others. (2022) presented an approach to the assessment of disclosure risks based on the training of the text classifier to assess the difficulties of the identity of the person in question on the basis of disinfected text.
2.4 Difference Privacy
Differential Privacy (DP) is a framework for the privacy of individuals in databases (Dwork et al., 2006). It basically acts on randomized answers to inquiries. The level of artificial noise taken in each answer is optimized to provide a guarantee that the amount of information learned per person is below the threshold.
Fernandes et al. (2019) applied DP to text data with ML techniques, adding noise to the model of the model. Their work focused on removing stylistic tips from the text as a way to ensure the author of the text to identify it. Feyisetan et al. (2019) Also apply the noise in the settings where the data of the individual's geographical location must be protected.
Recently, Sasada and others have. (2021) tried to address the noise issue needed for the DP, which causes the loss of the text obtained first by creating duplicates and then adding noise, thus reducing the amount of noise required. Krishna and others. (2021) tried to deal with the same problem using an algorithm based on auto-coders to change text without losing data mat. Finally, I am introduced to the DPBART, a DPBART system based on a pre-trained BART model, which aims to reduce the amount of artificial noise needed to achieve this privacy guarantee.
DP-oriented approaches generally lead to complete transforms of the text, at least in the case of reasonable values of privacy threshold. Therefore, these approaches are well suited for the generation of synthetic texts, especially for collecting training data for machine learning models. However, they are difficult to implement when disinfecting the text, since most of the text disinfection problems are maintained by the basic content of the text and editing only personal identifiers. This is especially true for judgments and health courts, as disinfected documents should not change the wording and semantic content transmitted in the text.



